

![]()
OpenShift v3
Introducción
OpenShift v3 incorpora muchos cambios en su arquitectura e introduce nuevos conceptos y componentes. Está construido para ejecutar las aplicaciones en contenedores Docker, soportando programación y gestión provistos por el proyecto Kubernetes, y añadiendo una capa de funcionalidades de despliegue, orquestación y enrutamiento.
Los cambios más significativos giran entorno al modelo de contenedores y cómo son monitorizados e interconectados. Kubernetes pods son un grupo de contenedores que actuan como una única Máquina Virtual: tienen una IP única, pueden compartir un sistema de ficheros y, normalment, tienen parámetros de seguridad idénticos. Agrupar contendores incrementa de manera exponencial el número de aplicaciones que pueden incorporarse a OpenShift. En lugar de enfocarse en un modelo de microservicios que excluya al resto de patrones, los pods permiten a los desarrolladores migrar las aplicaciones existentes que necesitan compartir recursos locales mientras se benefician de este modelo en contenedores.
En segundo lugar, se espera que los contenedores de OpenShift sean inmutables: la imagen contiene un snapshot en concreto del código de la aplicación junto con las librerias necesarias, mientras que cualquier otra configuración, claves o datos persistentes son acoplados al contenedor en tiempo de ejecución. Esto permite a los administradores, y a los integradores, seoarar el código y los parches de las configuraciones y los datos. Aunque sigue siendo posible modificar los contenedores, mantener los conceptos de alto nivel de constucción y despliegue de contenedores inmutables ofrece garantías de qué código se está ejecutando y dónde.
El tercer cambio importante está en el diseño del núcleo del sistema: OpenShift y Kubernetes se construyen como un conjunto de microservicios que trabajan al unísono mediante un REST APIs para modificar el sistema. Esos APIs estñan disponbles para integradores de sistemes, y esos mismos componentes del núcleo se pueden deshabilitar para permitir implementaciones diferentes. Un claro ejemplo es el API watch: un cliente se puede conectar y recibir información de los cambios en los pods (u otros objetos) y realizar alguna acción cuando el pod esté disponible (para localizar errores o cambios en los registros del sistema). OpenShift establece un control de acceso preciso sobre su REST APIs para permitir esta integración, lo que quiere decir que no habrá cambios que realice el sistema que no pueda hacerlos un integrador.
Extraído de la documentación oficial de OpenShift
Estructura
Después de toda esa morralla, ¿qué nos queda? Pues aclarar que este megatutorial estará basado en 3 máquinas virtuales CentOS 7, que yo montaré sobre KVM, cada uno sobre la plataforma que prefiera. Los requisitos de producción son bastante elevados, pero para este entorno de demostración voy a usar unas máquinas con recursos un poco más limitados. La estructura será la siguiente:
- Master
- CentOS 7.1 (aunque está disponible para Fedora >=21, RHEL >= 7.1, CentOS >= 7.1 y RHEL Atomic Host >= 7.2.4)
- 2vCPU
- 3072Gb RAM (mínimo recomendado 8Gb)
- 15Gb disco 1 (30Gb es lo mínimo recomendado)
- 10Gb disco 2 (para compartir por NFS y crear el registry)
- Node-1
- CentOS 7.1 (aunque está disponible para Fedora >=21, RHEL >= 7.1, CentOS >= 7.1 y RHEL Atomic Host >= 7.2.4)
- 1vCPU
- 3072Gb RAM (mínimo recomendado 8Gb)
- 15Gb disco 1 (lo mínimo recomendado es 15Gb, y aconsejan otros 15Gb mínimo en una partición, o dispositivo, adicional para el almacenamiento persistente)
- 10Gb disco 2 (almacenamiento persistente)
- NetworkManager instalado con una versión >=1.0
- Node-2
- Igual que Node-1
- Gateway
- CentOS 7.1 (aunque podría ser cualquier sistema Linux)
- 1vCPU
- 1024Gb RAM
- 5Gb disco (será sólo para instalar el DNS y Ansible)
¿Qué hay nuevo?
Arquitectura:
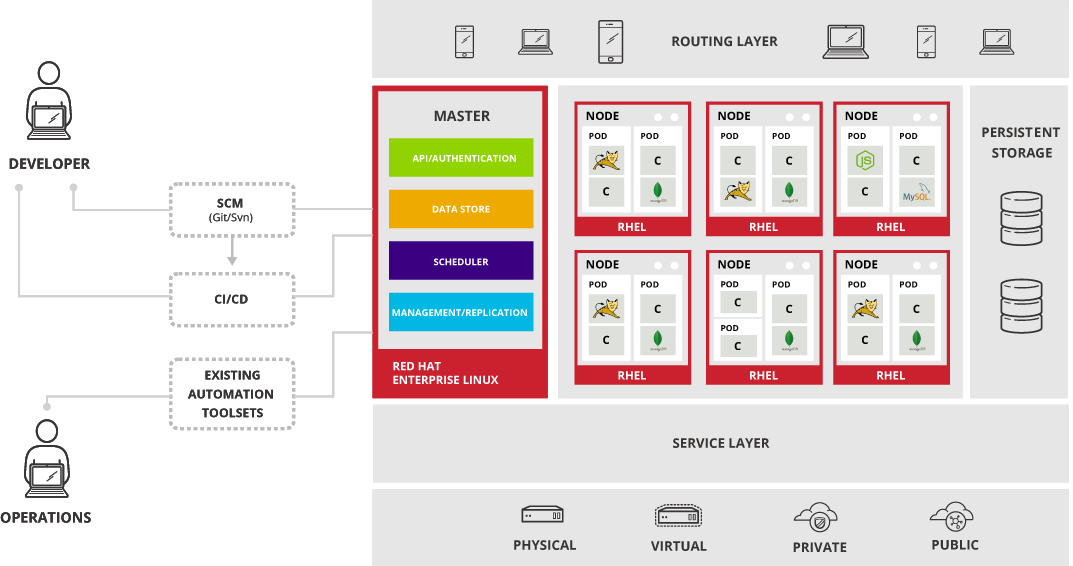
Master
Respecto a la versión 2 de OpenShift, esta nueva versión sufre un cambio drástico en su arquitectura, pero también en los nombres de los componentes. Lo primero que encontramos es que el Broker es renombrado como Master. y aunque su función sigue siendo la misma que en la versión 2, sus componentes no lo son. Su función será la de proporcionar:
- Autenticación: A través de diferentes mecanismos, aunque a lo largo de este tutorial usaremos la autenticación básica con HTTP
- Almacenamiento: Veremos como se crean las “aplicaciones”, y lo importante que será la centralización del almacenamiento
- Scheduler: Gracias a este componente, el Master podrá elegir dónde y cuándo desplegar las “aplicaciones”
- Gestión: A través de diversos APIs, podremos gestionar OpenShift tanto vía web como con clientes de línea de comandos
Otro de los aspectos que veremos del Master es que elimina la necesidad de instalar MongoDB y ActiveMQ para la gestión interna, ya que todo es orquestado por etcd.
Aplicaciones
Es el elemento principal para OpenShift, pero como su definición es muy abierta, el concepto de “aplicaciones” difiere bastante de la versión anterior.
Mientras que en OpenShift v2 una aplicación debía incluir un único componente web, o bien PHP o bien Ruby por ejemplo, con componentes adicionales como una base de datos, y que dicha base de datos no se podía desplegar sin el componente web.
En OpenShift v3 podemos tener tantos componentes como queramos, contenidos en un proyecto (más adelente hablaré de ello), enlazados de una manera flexible y, opcionalnebte, etiquetados para poder crear grupos o estructuras. Este nuevo modelo permite una única instancia de MySQL, o una compartida con componentes de JBoss, o cualquier otra combinación de componentes que imagines.
Imágenes
En OpenShift v2 disponíamos de “cartuchos”, que era una caja con librerías y binarios necesarios para desplegar el código de nuestra aplicación. El problema es que no hay una distinción clara entre el contenido del código de nuestra aplicación y el código del cartucho. Por ejemplo, una limitación es que no se es propietario del directorio home en los “gear” de nuestra aplicación. Aparte que no son un buen mecanismo de distribución para grandes binarios. Sin embargo, este concepto cambia gracias al uso de contenedores Docker en la versión 3. Una imagen es un conjunto de binarios y librerías, no modificables, una especie de snapshot. Para poder ejecutar código necesitamos un espacio de ejecución de dichas librerías y binarios, este espacio sí es editable, y su nombre es contenedor. Este contenedor se acopla encima de la imagen y añade el código de nuestra aplicación. Como ejemplo, supongamos que necesitamos una aplicación con PHP 5 y otra con PHP 7. Ambas tendrán una cantidad de librerías comunes, como los binarios del SO, aparte de Apache. Digamos que esos binarios los acoplamos en una imagen llamada “HTTP-BASE”. Esa imagen será la base para nuestras dos aplicaciones, pero ¿qué ocurre con PHP? Pues sobre esa imagen montamos un contenedor que instala PHP 5, y una vez instalado creamos un snapshot de ese contenedor y lo convertimos en una imagen llamada “PHP5”, y lo mismo pero con “PHP7”. Resultado, 3 imágenes. Ahora queremos ejecutar nuestra aplicacion con la versión 7, por ejemplo. OpenShift se encargará de lo siguiente:
- Monta la imagen “HTTP-BASE”
- Monta la imagen “PHP7”
- Crea un contenedor con el código de nuestra aplicación
- Monta la imagen “PHP7”
De ese modo, el código de nuestra aplicación está claramente desacoplado de las librerías y binarios que necesita para ser ejecutado.
Proyectos
En OpenShift v2 teníamos “domains”, en v3 se llaman “projects”. Prácticamente son lo mismo, un espacio en el que desplegar nuestras aplicaciones. Pero en la v3 se incluyen:
- Policies: que establecen lo que un usuario puede y no puede hacer
- Constraints: que establecen límites para cada uno de los objetos del proyecto
- Service Accounts: para establecer el acceso de los objetos del proyecto a diferentes recursos.
Y hasta aquí la introducción. En los siguientes posts nos adentraremos en la instalación y la configuración de nuestro cluster de OpenShift v3. Disponible aquí.
Hasta pronto.
Gracias por la intro. Muy bien explicado aunque el diseño de la arquitectura en la imagen no me queda totalmente claro, en base a los requisitos q pusiste en la descripción. Digamos q los nodos q no son máster trabajan en clustering , pero q tipo de contingencia habría para eso? Seguiré leyendo los demás post porque lo mismo lo tienes allí descrito.
Saludos