

![]()
OpenShift v3
Introduction
OpenShift v3 brings many architectural changes and introduces new concepts and components. It is built around the applications running in Docker containers, scheduling and management support provided by the Kubernetes project, and augmented deployment, orchestration, and routing functionality on top.
The most significant changes surround the container model and how they are monitored and interconnected. Kubernetespods are a group of containers that act like a single VM: they have a single IP address, they can share a file system, and they typically have similar security settings. Grouping containers together vastly increases the number of applications that can be brought to OpenShift. Rather than focusing on a microservice model to the exclusion of all other patterns, pods enable developers to port existing applications that need to share local resources while still benefiting from a containerized model.
Second, OpenShift containers are expected to be immutable: the image contains a particular snapshot of application code and its dependent libraries, while any configuration, secrets, or persistent data is attached to the container at runtime. This allows administrators and integrators to separate code and patches from configuration and data. While it is still possible to mutate your containers, the higher level concepts of build and deployments leverage immutable containers to provide higher level guarantees about what code is running where.
The third important change is in the core system design: OpenShift and Kubernetes are built as sets of microservices working together through common REST APIs to change the system. Those same APIs are available to system integrators, and those same core components can be disabled to allow alternative implementations. A great example of this are thewatch APIs: clients can connect and receive a stream of changes to pods (or other objects) and take action on them as the pods become available (to signal errors or log changes to the system). OpenShift exposes fine-grained access control on the REST APIs to enable this integration, which means there are no actions in the system that cannot also be done by an integrator.
Schema
After all of those verbose, what we need? This tutorial is deployed over 3 virtual machines CentOS 7 I am going to deploy in, you can deploy it wherever you want. Requirements for production are very high, but for this demo I will use machines with very limited resources. This is the components schema:
- Master
- CentOS 7.1 (it is also available for Fedora >=21, RHEL >= 7.1, CentOS >= 7.1 y RHEL Atomic Host >= 7.2.4)
- 2vCPU
- 3072Gb RAM (vendor recommended 8Gb)
- 15Gb disk 1 (this is the minimum recommended)
- 10Gb disk 2 (for NFS share and for internal registry)
- Node-1
- CentOS 7.1 (it is also available for Fedora >=21, RHEL >= 7.1, CentOS >= 7.1 y RHEL Atomic Host >= 7.2.4)
- 1vCPU
- 3072Gb RAM (vendor recommended 8Gb)
- 15Gb disk 1 (minimum is 15Gb, and 15Gb more in other partition or device for persistent storage)
- 10Gb disk 2 (persistent storage)
- NetworkManager installed with version >=1.0
- Node-2
- Same as Node-1
- Gateway
- CentOS 7.1 (it could be any Linux system)
- 1vCPU
- 1024Gb RAM
- 5Gb disk (only for DNS and Ansible)
What’s new?
Architecture:
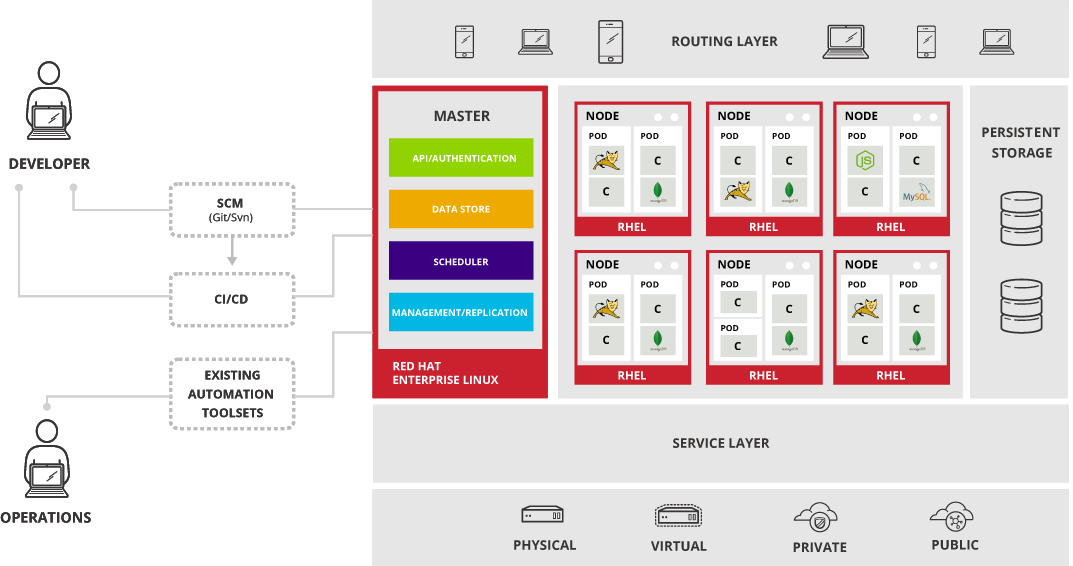
Master
This new version has a great change in the architecture from OpenShift v2 as well as the name of the components. First of all the Broker is renamed as Master, and while the function is the same as in v2 the components are not the same.Master is in charge of:
- Authentication: Through different mechanisms, but we are going to use HTTP authentication
- Storage: We will see how to create “applications” and how important storage is for them
- Scheduler: Thanks to this component the Master will be able to choose where and when deploy “applications”
- Management: It has several APIs that allow us to manage OpenShift both with command line clients as via web console
Another important aspect of the Master is it does not need to install MongoDB nor ActiveMQ for internal management as everything is stored in etcd.
Applications
The main component of OpenShift, but with many definitions depends on who is talking about “application”. It does not means the same for one person as for other.
While in OpenShift v2 an application should have one web component, and only one, i.e. PHP or Ruby, and other additional components as a database, that database never could be deployed without the web component
In OpenShift v3 we can deploy as many components as we want, contained in a project (lets talk later about this) flexibly linked together, and optionally labeled to provide any groupings or structure. This new model allows for a standalone MySQL instance, or one shared between JBoss components, or really any combination of components you can imagine.
Images
With OpenShift v2 we had “cartridges”, a box that contains libraries and binaries necessary to deploy the code of our application. The problem is that there is not a clear distinction between the content of the application code and the cartridge code itself. And also are not the best distribution mechanism for large binaries. But this concept changes in version 3 thanks to Docker containers. An image is a set of libraries and binaries, unwritable, like a snapshot. In order to run code we need a runtime for the libraries and binaries that is writable, and it is named container. The container is coupled over the image and adds our application code. i.e, we need an application running with PHP 5 and other withPHP 7. Both share libraries and OS binaries, as well Apache. So we have those components inside an imaged called “HTTP-BASE”. That image will be the base for our two applications, but what happens with PHP? We create a container over the image that installs PHP 5, and once installed we create a snapshot of the container and it becomes on a tiny image called “PHP5”; we do the same for “PHP7”. As result we have three images. No we want to run our application with PHP 7. OpenShift will do next:
- Prepares “HTTP-BASE” image
- Join up “PHP7” image
- Creates a container with our application code above images
- Join up “PHP7” image
Thous the application code is decoupled from the libraries and binaries needed to run.
Projects
In OpenShift v2 we had “domains”, in v3 it is called “projects”. But are essentially the same, a space to deploy our applications. OpenShift v3 there are several features not included in “domains” as:
- Policies: rules for which users can or cannot perform actions on objects.
- Constraints: Quotas for each kind of object that can be limited
- Service Accounts: Service accounts act automatically with designated access to objects in the project
Here ends the introduction. Next post will introduce installation and configuration of an OpenShift v3 cluster. You can access here
See you soon.